
„Ich weiß, dass ich nichts weiß.“
– Sokrates, gemäß Platon –
„Ich denke, also bin ich.“
– René Descartes –
Das folgende ist eine Kurzversion des ausführlicheren Artikels (auf English) das ich früher hier veröffentlicht habe.
In den vergangenen Wochen habe ich versucht, den Lernmechanismus eines tiefen Neuronalen Netzes besser zu verstehen. Dabei ist mir oft das Höhlengleichnis von Platon in den Sinn gekommen. Auf die Frage, wie Menschen sich geistig weiterbilden können, lässt Platon Sokrates im siebten Buch von „Der Staat“ mit einem Gleichnis antworten (siehe eine visuelle Darstellung in Abbildung 1): Demnach leben Menschen als Gefangene in einer Höhle, so gefesselt, dass sie nur auf eine Höhlenwand blicken können. Die einzige Lichtquelle befindet sich hinter ihnen, ihren Ursprung sowie den Ausgang können sie nicht sehen. Das einzige, was sie sehen sind die Schatten auf der Höhlenwand. Platon vergleicht hier die sinnlich wahrnehmbare Welt mit einer unterirdischen Höhle. Ziel muss es sein, sich durch Bildung daraus zu befreien und in die rein geistige Welt aufzusteigen. Mehr Details zum Höhlengleichnis erfahrt ihr hier.

Und tatsächlich: Als Menschen beobachten wir die Welt mit unseren natürlichen Sinnen. Unser Gehirn erweitert und verarbeitet diese Eindrücke zu sinnvollen Informationen. Diese Informationen setzen sich dann in unserem Kopf zu einem für uns verständlichen Gesamtmodell der umgebenden Welt zusammen. Theorien und Modelle, die unser Gehirn auf Grundlage unserer Beobachtungen produziert, sind somit stets mit Unsicherheiten behaftet. Denn was wir von der Welt sehen, hören, schmecken und ertasten, sind interpretierte Informationen.
Informationstheorie und Theorie des Informationsengpasses
Um diese Unsicherheit auf streng mathematische Weise zu messen und zu quantifizieren, hat Claude Shannon in den 1940er Jahren die Informationstheorie entwickelt. Um den Gehalt einer Information zu messen, wird die sogenannte Informationsentropie verwendet, oft auch nur Entropie genannt. Somit ist die Entropie nichts anderes als ein Maß für die Unsicherheit. Dabei sei betont, dass die Entropie als Maß der Unordnung schon davor im Zusammenhang mit der statistischen Physik der Thermodynamik (Wärmelehre) eingeführt wurde (durch Arbeiten von Ludwig Boltzmann und Josiah Willard Gibbs).
Auf das Höhlengleichnis von Platon angewandt, ist der Akt des Ausbrechens aus der Höhle ein Versuch, die Entropie – also die Unsicherheit des Wissens – zu minimieren, indem man die wahren Ursachen der beobachteten Phänomene untersucht.
Die Informationstheorie steht auch im Mittelpunkt eines vielversprechenden theoretischen Ansatzes zum Verständnis des Lernens in tiefen Neuronalen Netzen. Der spezifische Lernalgorithmus wird in der Literatur als Deep Learning (DL) bezeichnet. Entwickelt hat den neuen Ansatz, der als „Information-Bottleneck-Theorie“ bezeichnet wird, Naftali Tishby, Professor für Informatik und Rechnergestützte Neurowissenschaft an der Hebräischen Universität von Jerusalem, in Zusammenarbeit mit Kollegen. In der Summe beschreibt diese Theorie den Lernmechanismus in Neuronalen Netzen als einen zweiphasigen Prozess zur Komprimierung einer riesigen Datenmenge mit all ihrem Informationsgehalt in eine kürzere Darstellung.
Kompromiss zwischen Kompression und Vorhersage
Betrachten wir als visuelles Beispiel ein bereits trainiertes Neuronales Netz. Dieses wurde auf Basis eines großen Bilddatensatzes trainiert, der verschiedene Objektklassen (zum Beispiel Menschen, Tiere oder Autos) enthält. Werden dem trainierten Netz später neue Bilder eingespielt, soll es entscheiden, ob bereits erlernte Objektklassen in dem Bild vorhanden sind. Tishby und seine Ko-Autorin Noga Zaslavsky formulieren in ihrer Arbeit „Deep Learning and the Information Bottleneck Principle“ aus dem Jahr 2015 das Ziel von Deep Learning „als informationstheoretischen Kompromiss zwischen Kompression und Vorhersage“.
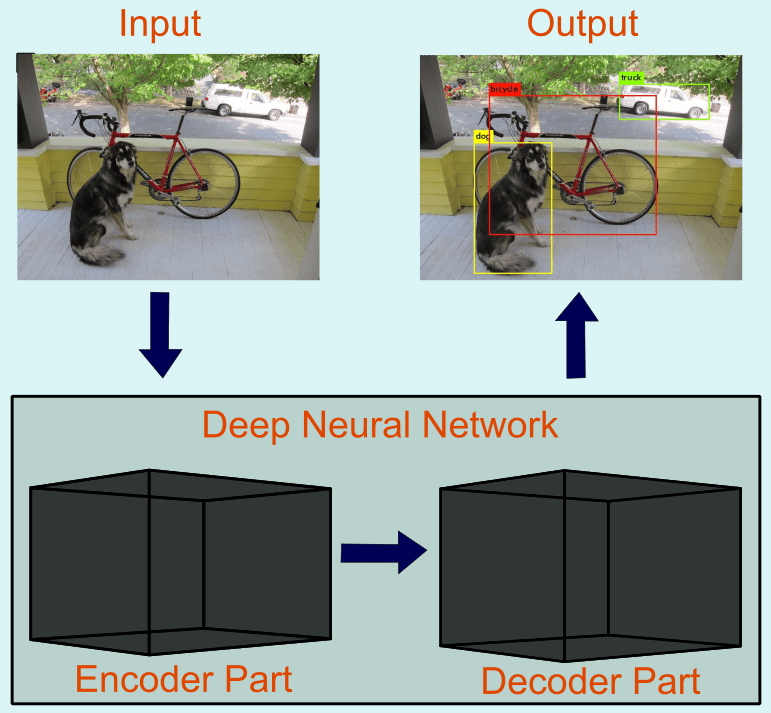
Abbildung 2: Schematische Darstellung eines generischen Neuronalen Netzes, Verarbeitung eines Eingabebildes (Input) und Ausgabe (Output) eines Bildes zusammen mit den Objektbegrenzungskästen.
Ein eher abstraktes Schema eines tiefen Neuronalen Netzes ist in Abbildung 2 zu sehen. Der erste Teil, der sogenannte Encoder, extrahiert relevante Informationen aus dem gesamten Eingabedatensatz. Der zweite Teil, der so genannte Decoder, klassifiziert den Inhalt (Mensch, Tier, andere Objekte) aus den extrahierten Merkmalen, die im Encoder dargestellt werden. Im Grunde ist der Encoder das komprimierte Destillat an essenzieller Information über den Datensatz – mathematisch kodiert in die Millionen bis Milliarden Parameter eines tiefen Neuronalen Netzes. Entsprechend ist der Decoder später in der Lage, diese Information zusammen mit der neuen Bildeingabe so zu interpretieren, dass als Ausgabe die Entscheidung herauskommt, was sich im Bild befindet.
Das Konzept der Informationsebene
Um besser zu verstehen, wie die „Information-Bottleneck-Theorie“ das Wesen von Deep Learning erfasst, verwendeten Tishby und Zaslavsky das Konzept der Informationsebene in einem zweidimensionalen kartesischen Koordinatensystem (siehe Abbildung 3). Hier zeigt die $x$-Achse den im Neuronalen Netz kodierten Informationsgehalt über die Eingabe, während die $y$-Achse den Informationsgehalt quantifiziert, der über die Ausgabe-Klasse innerhalb des Netzwerks kodiert ist.
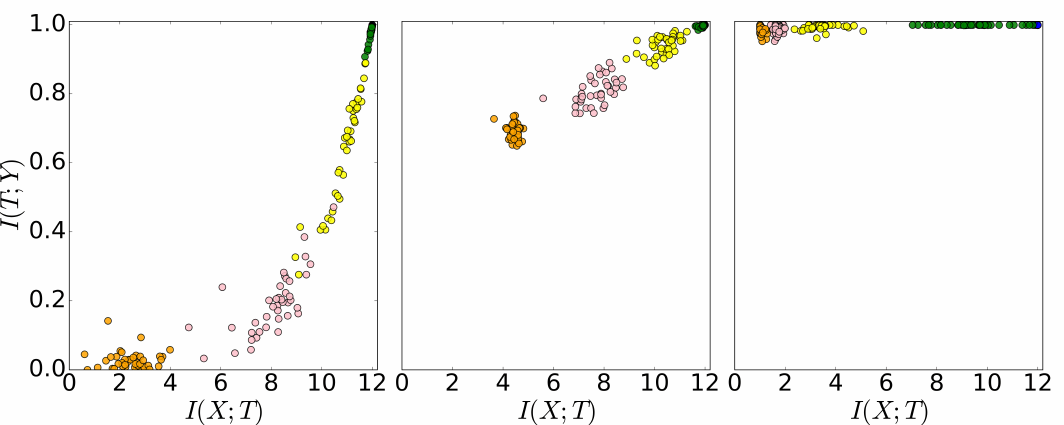
Abbildung 3: Momentaufnahmen von Schichten (verschiedene Farben) randomisierter Netzwerke während des Trainingsprozesses in der Informationsebene (in Bits). Links: anfängliche Zufallsgewichtung; Mitte: Verteilung nach einigen Trainingsdurchläufen; rechts: Verteilung nach Abschluss des Trainings (ganzes Video). Abbildung entnommen aus R. Schwartz-Ziv und N. Tishby (2017).
Mit der Informationsebene können wir den gesamten Trainingszyklus von Dutzenden bis Hunderten Neuronalen Netzen gleichzeitig veranschaulichen. All diese einzelnen Netzwerke können dabei mit unterschiedlichen Architekturen und unterschiedlichen Anfangsparametern versehen sein, während sie mit demselben Datensatz trainiert wurden (Eingabe und Ausgabe).
Eine Prozedur zum Vergessen
Im Allgemeinen nimmt der Anteil von Informationen über die Eingabe nach vielen Lern-Durchläufen tendenziell ab. Man kann sich dies als einen Prozess des Vergessens vorstellen. Betrachten wir das Beispiel einer Aussage darüber, ob es in einem beliebigen Bild Menschen gibt oder nicht. In der Phase, in der sich das Training des Neuronalen Netzwerks lediglich damit befasst, Eingabebilder mit der Klasse Mensch abzugleichen, könnte das Netzwerk jedes Bildmerkmal als relevant für die Klassifizierung halten.
Es kann zum Beispiel sein, dass die ersten Daten des Trainingsdatensatzes hauptsächlich Bilder von Menschen auf Straßen in Städten enthalten. Dann lernt das Netzwerk, dass das Merkmal Straße offensichtlich für die Klassifizierung von Menschen in Bildern relevant ist. Je mehr Bilder von Menschen das Netzwerk ohne Straßen sieht – stattdessen zum Beispiel in der Natur oder in Häusern – desto schneller vergisst es die Relevanz des spezifischen Merkmals Straße für die Klassifizierung von Menschen auf einem Bild. So können wir sagen, dass das Netzwerk jetzt gelernt hat, die spezifischen Merkmale der Umgebung so weit zu abstrahieren, dass es auch in anderen Umgebungen Menschen sicher erkennt. Umgekehrt ist daraus auch logisch ersichtlich, dass ein Netzwerk, welches auf sehr einseitige Daten trainiert wurde, auch sehr einseitige Entscheidungen treffen wird. Beispiele wären hier negative Entscheidungen aufgrund von Geschlecht, ethnischer Herkunft, Alter und so weiter.
Dank der Bemühungen von Tishby und Zaslavsky steht uns mit der Theorie des „Information Bottleneck“ ein vielversprechender Kandidat für die gründliche Untersuchung des Lernens in Neuronalen Netzen zur Verfügung. Moderne Neuronale Netze erreichen leicht einen Umfang von mehreren Milliarden Parametern. Die Theorie kann hierbei als Flaschenhals dienen und die Datenfülle mit den Achsen der Informationsebene begrenzen. So reduziert sie die Datenmenge der Parameter eines Neuronalen Netzes so weit, wie es für das Verständnis des Lernens nötig ist.
Ausblick
In einem nächsten Teil diskutieren wir weitere Details der Theorie. Dabei untersuchen wir zunächst die Frage, welche Rolle die Menge der Trainingsdaten für das Endergebnis des Trainings spielt. Wir werden dann sehen, inwieweit die beiden Phasen des tiefen Lernens den Drift- und Diffusionsphasen der Fokker-Planck-Gleichung ähneln. Dies ist eine weitere faszinierende Ähnlichkeit mit der statistischen Mechanik.