
It is quite remarkable how well the allegory of the cave by Plato depicts our fate as humans to only acquire knowledge about the world with a degree of uncertainty that is never zero. This is because we observe the world through our natural senses, while our brains interpret these observations and forms ever complex knowledge systems, like culture, philosophy, and science.

This famous parable also paints well the situation that we have in data science. Recently, Dr. Cassie Kozyrkov, Chief Decision Scientist at Google, wrote a nice Blog post on what she calls the “saddest equation in data science”:
Data + Assumptions = Inference.
This equation is quite simple, but essentially deep and true when it comes to Statistical Inference and Data Science. We take data, put some assumptions on top and this gives us predictions on previously unseen data points or future observations. There is specifically no way of taking out the assumptions from this equation. In essence, our brain performs “data science”, only that this “data science” is much more complex. Though it runs manifolds of different “inference algorithms” on very different input data (vision, hearing, olfactory, tactile) in parallel, and integrates all these observations into a meaningful overall picture, the above equation still holds. At the end of the day, the interpretation of the “data” through our senses inside the brain and the “inference” upon this “data” is not done without assumptions.
All decision making is based upon assumptions. When I planned my visit to the Desert Fest Stoner Rock festival 2020 in Berlin, I assumed no worldwide Pandemic to cancel all big events. When I go for dark chocolate ice cream, I mostly assume it will taste amazing. When I decide to go out without an umbrella, I’ve been assuming that it will not rain. There are assumptions all over the place. Once again, I would like to refer to Cassie Kozyrkov:
“Two people can come to completely different valid conclusions from the same data! All it takes is using different assumptions.”
source.
Of Cats and Non-Cats: An Experiment in Data Science
Still, in Data Science we often tend to approach problems too much technology-first-centric. I mean by that the tendency to develop “shiny” algorithms to automate any decision and then think about the decisions, outcomes, and goals at the very end, if at all.
Here, it is my aim to convince you that there is a very useful discipline out there which enables us to thoroughly define the goals/objectives of a decision first, then construct a graphical picture of the whole decision processes. At the end, when the picture is complete, we go over to the micro-decisions which technology/analytics/statistics tool we want to insert at each edge connecting any two nodes of the decision graph.
But first let me try to convince you visually why Data Science, AI or Machine Learning (ML) are not enough for responsible decision making, particularly in the realm of health science and health tech. For that let us play a game, which I did borrow from another inspiring blog post by Cassie Kozyrkov. In this game, I show you six images with animals (Fig. 2) and you have then the task to put “cat” or “no cat” label on them. And I will be mean and just will only allow you to put either one of these two labels on the image and nothing else.

It seems quite easy for us to label the images 1 to 5. But things get complicated, once we are at image 6. Here, we are tempted to put something like wild cat, big cat or somewhat within the family of cat. But as I was mean and only allowed you to put “cat” or “no cat” on the images, you might now feel kind of frozen in between the decision … “Cat or no cat, that is the question”, would the (Cat) Hamlet say. Our friend the AI/ML algorithm will not bother much with this question and just will decide according to the image features that it had memorized during its training on a particular training set. It might decide here for either one of the labels, with specific confidence value maybe, but nothing between.
And that is essentially our dilemma: We must first clarify the objective of this decision. Otherwise, the whole decision does not make any sense. If we have the goal to detect just “cuddle cats”, then we should maybe either exclude the tiger in image six from the cat class or adapt the labeling to something like “cat for cuddle” versus “cat not for cuddle”. Otherwise, if you are someone like the Tiger King, then you might even include the tiger into the “cat for cuddle” class.
Explainable AI: How an Algorithm Decides
Besides the issue of non-clear objective, there is another major problem of applying an AI algorithm just for its own sake. That is the so-called short-cut learning in deep learning. This can have catastrophic effects, when undetected, in particular in medical area. But there is solution at the horizon, continuously developed by researchers in the regime of explainable AI. Researchers from the Technical University (TU) of Berlin and Fraunhofer Heinrich-Hertz Institute for Video Coding developed very useful tools to assess image-based AI decisions and then trace the decision back to the image features that led to the decision. In a recent publication they discussed some of their inspiring results of analysis. One example which they show is an AI algorithm that was trained to classify horses in images. Then the application of their decision assessment tool clearly has shown that the algorithm has learned to classify the horse in the image solely upon the existence of the artist source tag (see Fig. 3). Some more examples are presented and discussed on the website of TU Berlin.
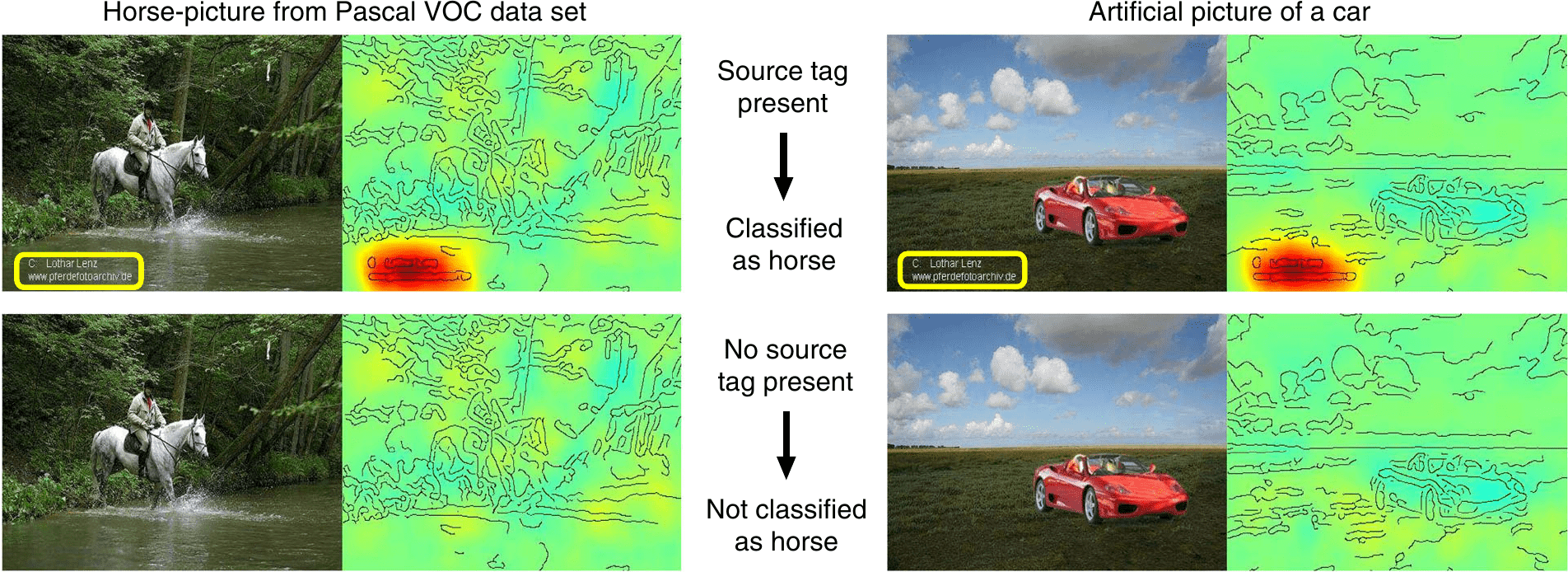
©Nature Communications/CC BY
To my view these examples that the authors of the above paper discuss, show “over-compression” of the learned representation. As I discussed in my last blog postings on the Information Bottleneck theory of Deep Learning (part 1 and part 2), the process of deep learning employs two phases. The first phase is just a fitting of input data (images) to corresponding class labels (horse). The second phase is characterized by the compression of the encoded information within the neural network. Essentially, the algorithm that classifies the images as containing a horse has found just one very optimal “short-cut” feature allowing it to classify the images. This short-cut feature is the source tag. It must be noted here though that the above example (horse classifier) is not a deep learning neural network, but instead a Fisher Vector classifier. Still, the utilization of Fisher vectors for extracting local features from images for classification is essentially applying a compression/reduction of encoded information to describe images according to different classes (horse/no horse). In this sense, the short-cut learning issue still applies.
Whose Fault is the Bad Decisions of an AI Algorithm?
So, who is to blame here? Is it the trained AI algorithm? Is it the data? Or both? To my opinion neither one of these is to blame. We are to blame, nothing else. We created the algorithm, we created/curated the underlying data, we developed and applied the learning mechanisms, we supervised the learning process, and finally we are to blame when we deploy the algorithm without assessment of its “good” and “bad” decisions.
Matters are even worse, and you must be very strong now. I must take away the illusion from you of thinking that we humans have not the problem of short-cut learning. Though our brains are so much more complex than our current AI algorithms, we still are falling for the “short-cuts”. We also do the “over-compression/over-generalization” game. Just think of widespread racist and discriminating prejudices that are still circulating today, like “Women can’t drive”, “Mexicans are criminals” or conspiracy myths like “Global warming is a communist hoax” to “Corona is a Psy OP”.
The Four Pillars of Common Sense
Despite this devastating message, there is hope for us. Evolution blessed us with common sense that we can and must use if we are not wanting to fall for the cozy short-cuts. Yann LeCun, one of the founding fathers of Deep Learning considered our “common sense” to be built upon four major abilities, shown in Fig. 4. The current AI algorithms at our disposal are lacking in all but one element of it (see Fig. 4).
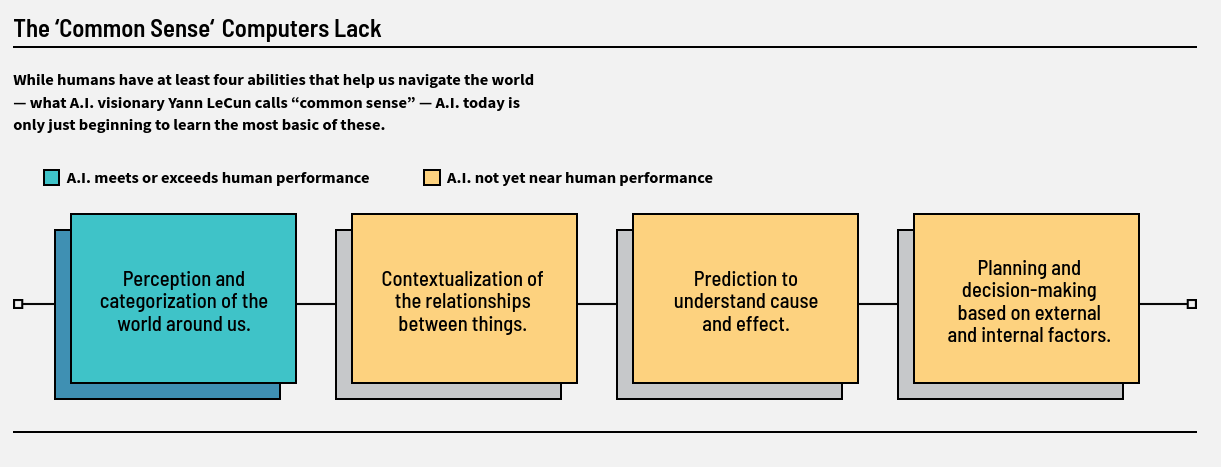
The particularly important elements of that common sense for decision making in a complex and uncertain world like ours are those in which the current AI algorithms are lacking. These are shown in the image above on yellow background. I would even go as far as to state that, though all humans have the ability to use contextualization of relationships, comprehension of cause and effect, and planning and decision making, most don’t use these valuable abilities. Instead, we fall back into perception and categorization too often since it is so comfortable and the other three are too complicated to follow always in daily life. That is the reason for our prejudices exemplified above.
What is Decision Intelligence?
The four pillars of common sense are also at the heart of a new discipline for systematic and rational decision making in complex political, economic, and many other systems. This is the discipline of Decision Intelligence (DI). In her introduction post on DI, Cassie Kozyrkov termed it also as Data Science++ or Machine Learning++, since it is a discipline to augment AI with common sense reasoning to achieve better decisions.
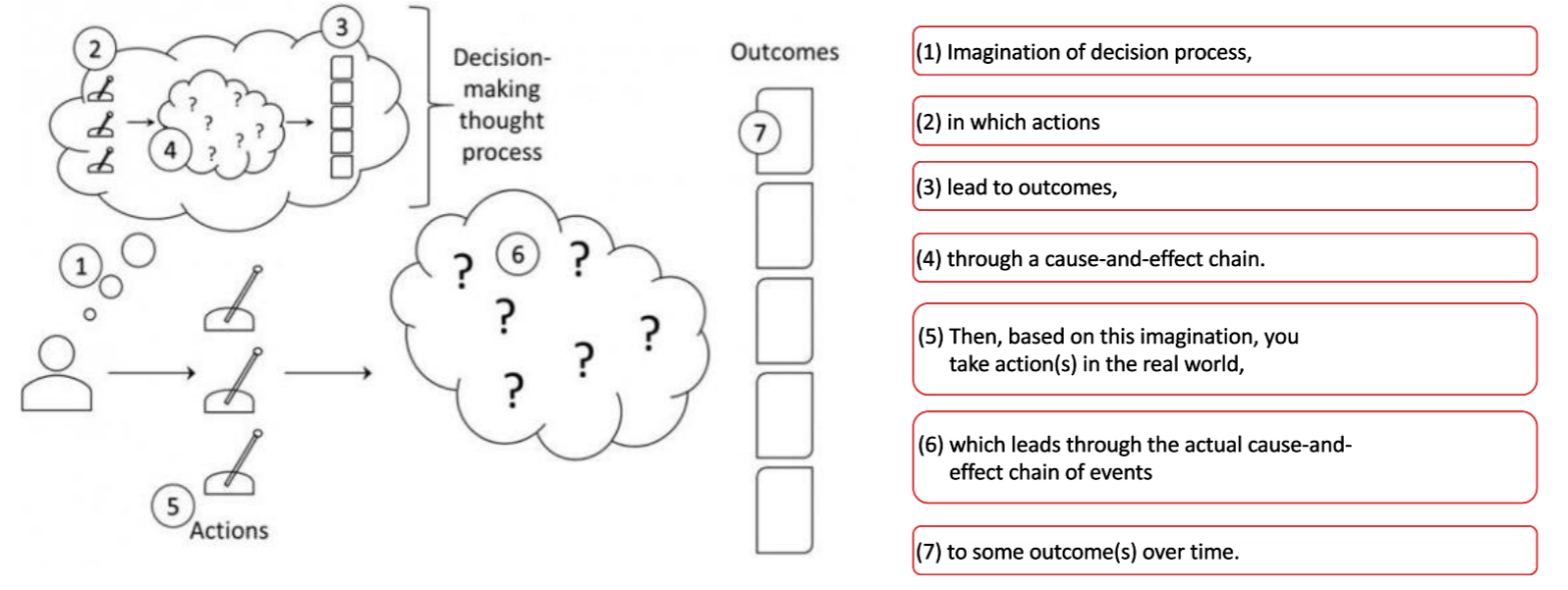
We can understand Decision Intelligence better, if we consider first in principle, what a decision is and how we as humans make decisions, from the imagination of the decision process in our head up to the actions we take within the real world, yielding real outcomes (see Fig.5).
Out of that scheme of decision making we can build our own decision model for any project in graphical terms. In Fig. 6, a schematic template of that graphical representation is shown. Lorien Pratt, one of main founders of DI as a discipline has termed that template as Causal Decision Diagram (CDD). The CDD of a particular project is formed out of simple building blocks and these are connected with each other by our assumptions about the project and the decisions to be made.
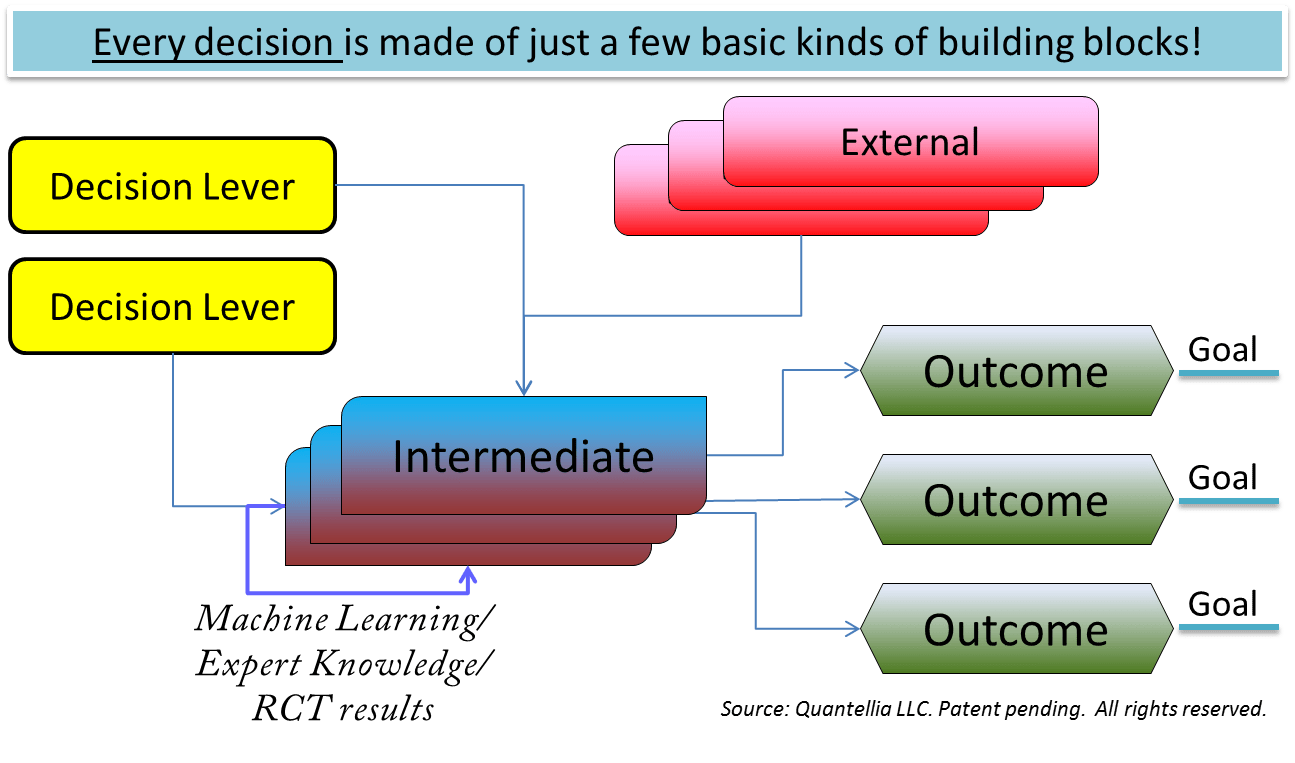
When the CDD is created, we first and foremost define the goal(s). Then, the decision levers can be specific choices of action, e.g. potential medical treatments. The externals are set by the environment. These can be the budget for the project, the IT system of clinics, etc. Intermediates are potential direct or indirect effects of the decision levers, for example benefits of specific medical treatments, side-effects of decisions, etc. Finally, the outcomes are yielded, both desired and the undesired.
The CDD scheme clearly shows the holistic nature of DI. At each edge of the graph we could insert an AI/ML algorithm to generate data-based knowledge, whereby we reach a more informed decision. But it has to be noted that insertion of an AI algorithm is not mandatory, it just depends on the nature of specific edge between the two nodes of the graph. If the relation between the action and the potential outcome is factual (domain expert knowledge), then there is no need for AI. Instead the facts will inform us. If the relation between the nodes are of analytic/mathematical type, then the mathematical analysis will inform our way to decision here. If our knowledge at an edge is uncertain, then data-based statistical inference will help us out. An example for such uncertainty can be the question if a specific medical treatment yields one particular effect or not. In the latter case, we could also insert a randomized controlled trial or data-based causal inferencing methods to inform us.
Even a Toolbox Needs a Decision Maker
ML/AI algorithms are great tools to detect patterns in our data, to predict and classify based on these patterns, to show us ways for decision. They are additional tools within the scientific inference toolbox that was filled with great tools by our predecessors and will be filled with more great tools by our descendants. The toolbox will enlighten our way through complexity, show us avenues for decision. But at the end of the day, the toolbox will not free us from making the decisions.
As Morpheus would say:
